
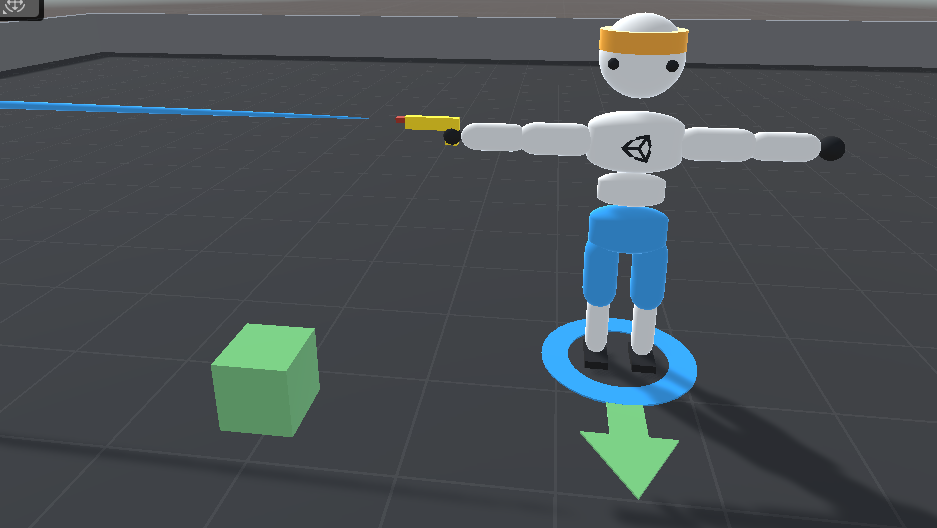
Ever wondered what it would be like to play a video game against an AI that was actually intelligent?
Most video game NPCs use preprogrammed behaviors that never change, so they're more like animatronics than robots. I wanted to see if I could make a video game NPC that would learn a task through experimentation and machine learning rather than being on rails, so today we're making a terminator. Skynet here we come.
I used Unity for the 3D environment and retrofitted the Walker example project from Unity's ml-agents, which lets you use Python to run reinforcement learning algorithms. I used the PPO algorithm (Proximal Policy Optimization), which gets state-of-the-art results and is known for being stable and reliable. PPO works great to teach a robot how to walk, but can we teach our agent other things? Let's start by giving it a laser gun.
Like other reinforcement learning algorithms, PPO agents learn by taking actions, getting a reward or punishment, and then learning from their mistakes to figure out the best strategy to maximze their reward per episode. They start not knowing anything, and their actions are completely random.
As you can see, it doesn't even know how to stay standing, much less shoot the green box that serves as its target. I've had trouble teaching agents in the past when the rewards are sparse, so in order to help it learn, I gave it three concentric hitboxes extending from the laser pistol. To encourage it to shoot the target, I gave it a small bit of reward for aiming the gun so that the target is in the outer hitbox, a little bit more for the inner one, and even more for the tiniest hitbox. If it fires while the target is in one of these hitboxes, the reward was doubled. I also wanted to teach it to conserve ammo and not fire randomly, so I gave it -0.5 reward if it fired when the target wasn't inside one of these aiming hitboxes. Hitting the target gives it +1 reward and falling on the ground gives it -1.
The first two tries training it were unsuccessful, and mostly consisted of bugfixes and playing with different hyperparameters. By the third iteration, the simulation was bug-free and the agent was learning. After about 5 hours of training and 30 million episodes, I got some interesting results.
This is a huge step in the right direction. The agent learned to stand upright and aim pretty accurately. It even hit the target occasionally. But I noticed it had stopped learning, and the solution it converged on seemed always to fire near the target, but almost never actually hit it. When I realized what had happened I had to laugh. The robot outsmarted me.
It doesn't know what it's supposed to be doing, it just knows that some things give it reward and others don't. The agent found a clever way to get easy reward and stubbornly stuck with it. I had set the reward for hitting the target only slightly higher than the rewards for shooting near the target. The agent figured out that if it actually managed to hit the target, it would respawn, potentially in an area it wasn't used to shooting towards yet. If that happened, it would miss out on reward while it was turning around and it might fall off balance and get penalized. It just wasn't worth the risk to actually shoot the target, so the agent was intentionally missing. It was clear what needed to change.
It doesn't know what it's supposed to be doing, it just knows that some things give it reward and others don't. The agent found a clever way to get easy reward and stubbornly stuck with it. I had set the reward for hitting the target only slightly higher than the rewards for shooting near the target. The agent figured out that if it actually managed to hit the target, it would respawn, potentially in an area it wasn't used to shooting towards yet. If that happened, it would miss out on reward while it was turning around and it might fall off balance and get penalized. It just wasn't worth the risk to actually shoot the target, so the agent was intentionally missing. It was clear what needed to change.
I upped the reward for hitting the target to +2, but the same thing happened. Frustrated, I took drastic measures and set it to +50, lowering the aiming and near miss rewards to tiny fractions. I left the falling penalty at -1. This time it worked. Maybe a little too well.
After five more hours and 28 million episodes, the new agent quickly became a crack shot. Unfortunately it also decided that standing up was no longer a priority. I can hardly blame it. Based on the rewards I set, it could fall over 49 times and as long as it still hit the target on the 50th, it would have a positive reward. This was funny to watch, but hardly the T1000 I'd been dreaming of. If only we could combine these two agents, we'd have a robot to rival Arnold. Time to try again.
Agent #6 took longer to converge, and didn't stop learning until around 7 hours in. That was a good sign. Taking a peek into the 28 copies of the agent all trainging together at around 30 million episodes made me think of battle school from Ender's Game.
At 40 million episodes, the agent essentially mastered the task. The secret sauce was finding a balance between the reward for hitting the target and the punishment for falling over. I kept the aiming and near miss rewards as tiny fractions and the falling penalty as 1, but changed the hit reward to 10. The results speak for themselves. It can basically shoot the targets faster than I can see them appear.
Hope you enjoyed my little side project! What should we teach our agent next? How to shoot multiple targets with 4 arms? How to play a musical instrument? What would happen if they competed against each other in laser tag? I welcome any questions or suggestions at contactmacjgames@gmail.com